This article describes two different approaches for loading data from a source system into a staging area of a Business Intelligence system. Full Load and Delta Load.
Both approaches can be used to load a table like structure like below from either a database table, a CSV file or a Web Service into a staging table.
| OrderId | CreateDate | Item | Price |
|---|---|---|---|
| FH43H | 07-05-2013 | Shoes | 99 $ |
| GJ33A | 07-05-2013 | Boots | 159 $ |
| XFV33 | 08-05-2013 | Shirt | 29 $ |
Full Load
Full Load means that with every load the entire order table is loaded into the fact table. In order to avoid duplicate records the fact table would be flushed before every load with this simple SQL statement:
Truncate table FactOrders
The full load can then be implemented with a simple data flow in MS Integration Services.
Obviously the drawback of the solution is that the bigger a table is the longer the process takes.
Actually with every load as little data as possible but as much as neccessary shoud be fetched
This is basically the idea of a delta extraction mechanism. How the actual pull process is implemented depends on the type of data source. Sometimes it might be an SQL statement, sometimes an API Call over an HTTP Rest interface or somtimes just copying a csv file over FTP. In this example we assume the pull process is implemented as an SQL statement.
Types of Data Sources
Basically you can categorize data sources into 3 possible types depending on their delta load capabilities:
- Incapable of delta load, so you will always have to load all the records provided by the data source
- Capable of overlapping delta loads. This means a subsequent load may contain records that have already been contained in a previous load
- Capable of guaranteed duplicate free delta load
Type 2 and 3 data sources are kind of “intelligent” which means we can query them with some kind of “offset information”. Subsequently I will the call this offset information Delta Handle. Looking at the sample order table we see that this data source is of type 2. It is capable of overlapping delta loads based on the Delta Handle column CreateDate. Every run of a delta load will subsequently be called Request. A Request has a unique incrementing number, its RequestId and represents all the records that have been loaded from the source system.
Delta Load
With CreateDate there is one column that is incrementing on a daily basis. Imagine an extraction took place on 07-05-2013 11:00pm and then at 11:30 some shopper bought a pair of shoes .
So if only orders with a CreateDate > 07-05-2013 would be considered for the next extraction then the 11:30 order would get lost.
So with the next load all records that have a CreateDate of >= 07-05-2013 need to be loaded, which means that some records are loaded twice. How to cope with duplicate records and intersecting Requests will be described later on.
Right after the load has finished today´s date needs to be stored in a separate logging table in order to have the correct offset for the next run.
As an example the above table structure shall be loaded into an Business Intelligence system
The table might be available as an SQL table on a remote SQL Server or as a daily CSV file export on a remote FTP server. In the following it will be described how a stable and perfomant delta loading mechanism can be implemented to this case. The scenario will focus on loading from a SQL table but could easily be adapted for example for CSV files.
Delta Load Infrastructure
In order to implement a performant and reliable delta mechanism 2 types of tables need to be created in the staging area, one buffer table and one staging table
Buffer Table
The Buffer table is a perfect clone of the source table (or source data structure), ideally with the same keys and constraints. The source table key will subsequently be called business key so that it can be distinguished from the staging table key described later on. The buffer table will temporarily hold the content of each request. By having a buffer table in the staging area we can process the recently loaded request data with SQL which otherwise would not be possible. A Buffer table will always have the prefix BUFFER_ followed by the source table name (e.g. BUFFER_CUSTTABLE).
Loading the Buffer Table
When loading to the buffer table we always try to load as little data as possible but as much as necessary from the source system. This is achieved with an SSIS Packaged and a .Net script that dynamically generates an SQL statement that is then fired against the sources system. This .net uses the previously defined delta handle and the generated SQL script selects all the records that have delta handle greater or equal than the last buffer load. The DeltaLoader will also generate the correct .net script:
Staging Table
The staging table will hold all the data that has ever been loaded from the source system, so it is not temporary but permanent (of course it may be flushed at some point).
The staging table needs to contain all the information (columns) from the source table, but besides that it also needs to keep track of when a record was inserted, when it was changed and in some cases what the change history was. To fullfill these requirements 3 more columns are added to each Staging table:
- _CreatedRequest
- _ModifiedRequest
- _MostRecentRecord
By adding these 3 columns two different staging behaviors can be implemented: MostRecent-Staging or Historizing-Staging
Loading the Staging Table
The Staging table is always filled from its corresponding buffer table right after the buffer table has finished loading. After the data has been transferred from buffer to staging table the buffer table is flushed. Depending on whether the staging table has MostRecent-Staging and Historizing-Staging behavior different SQL scripts are used for filling the table. For both types of tables the SQL Merge command is used.
MostRecent-Behavior
When in MostRecentBehavior records that already exist (whose business key already exists in the staging table) are overwritten in case their delta handle is newer. Otherwise they are just ignored. So no duplicate records will be created. The field _CreatedRequest stays the same however _ModifiedRequest will be set to the current request number.
The Primary Key of a MostRecent-Staging table is always the BusinessKey from the source system.
Historizing-Behavior
With Historizing behavior existing records are never overwritten but changed records are always appended to the staging table. Records that have not changed are ignored. Every newly inserted record will get the _MostRecentRecord field set to 1. If an older version of the record exists its _MostRecentRecord will be set to 0.
The Primary Key of a Historizing-Staging table is always {BusinessKey , _CreatedRequest} . With Historizing Behavior the _CreatedRequest and _ModifiedRequest are always the same.
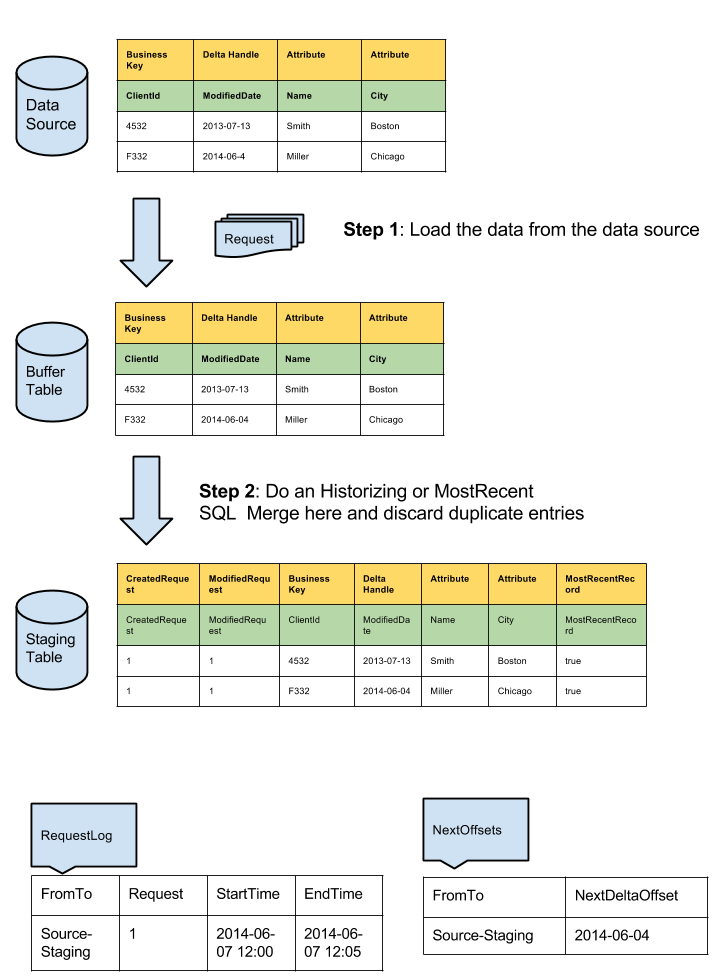 Schematic delta load process
Schematic delta load process
Usage Scenarios
In a Data Warehouse there a two types of tables, fact and dimension tables. Depending on the type of a table Historizing or MostRecent staging is more appropriate.
Dimension Tables
With dimensions tables you can use both types of staging. In case the dimension is modelled as a “slowly changing dimension” you shuld use Historizing staging otherwise if you do not want to track changes MostRecent staging is fine.
Fact Tables
With fact table you only want to use MostRecent staging to avoid duplicate records.
Logging
In order to fill the buffer table an offset information for the delta handle field is required (e.g. a date for field MODIFIEDDATETIME) After each source → buffer load this information is stored in a tabel called “NextOffsets”
Addtionaly to keep track of passed delta loading runs every run is logged into a table called “RequestLog”.
Software Tools
I have written a .net Tool to help you with creating SQL code for delta load processes on SQL Server. Feel free to check it here: Delta Loading a Table with SqlDeltaGenterator
Sum Up
A delta load process divides up into 2 steps:
- loading as little as possible data from source into buffer table
- merging data from buffer table into staging table